About Yoko
(well look at that, turns out there exist fancy words for this all, like 'knowledge representation' 'ontology' and 'Natural Language Processing, and the description of Yoko would be a rule-based system.' Moreover most of what I'm trying to do was already tried - and considered hopeless - in the seventies. Whatever, reinventing the wheel is still inventing which is fun, even if it doesn't bring fame or whatever. And I'm having a ton of fun trying to understand the mechanisms and structures in how we think and communicate about the world around us. What's more, the buzz around the semantic web has made 'ontologies' all cool and dandy again it seems)

Yoko is a chatbot written from the ground up using *gasp* PHP and MySQL (if all you have is a hammer, or rather your favorite tool is a hammer...).
It does not rely primarily on matching language patterns with possible 'templated' responses (like ELIZA or ALICE or AIML-based bots like these), or by learning question-response patterns from earlier conversations (like jabberwacky, cleverbot).
Instead, it tries to build up and retrieve from, a structured database of symbols of 'general knowledge' of the world, as well as specific events taking place and the current conversation (short term memory if you will), reason on those using specific rules, and convert between that and natural language. It's chatbots, old fashioned way.
So, if anything, I consider the spiritual ancestors of Yoko to be oldie bots like SHRDLU (check out that readme file!) and TUTOR (check out the phd thesis where Daniel Bobrow describes the latter, it's a pretty cool read). I think you could also say Yoko is a 'rule-based system.'
Unfortunately that means Yoko is not as full of witty pre-fed comebacks as her chatbotty siblings, and that she will keep on nagging until she properly understands something.
The goal is for Yoko to appear as smart as, say, an annoying 5-year old. (including the nagging) But hopefully, at least she won't feel too 'scripted'.
Another thing chatbots often don't seem to do is to initiate conversation, they just react to what you say. If you say nothing, Yoko should eventually try to make conversation, be it about the topic at hand, or at least about something she has been 'wondering about' to fill gaps in her knowledge ('are ALL fruits yellow or is that just bananas?') or whatever.
The 'AI philosophical' conviction behind Yoko
It is very, very likely that, like generations of AI folks - and particularly amateurs like myself - before me, I am hopelessly naive and futile in this project (but boy is it fun).
So to prevent you from wasting too much reading time on what you consider naive crackpottery, here it is up front:
I believe a realistic 'reasoning' conversational agent that displays 'understanding' (and, yes, perhaps some day passes the infamous Turing test) CAN be constructed based on reasoning on a knowledge base of classes, properties, instances, actions, simulated and real events, hypothetical events and their causal links, simulated (but consistently remembered) preferences of the agent regarding all of these, etc...
What's more, the aspects often quoted as being outside of the 'manipulating symbols' part of our thinking but vital to our 'inteligence' - like, say, spatial reasoning or episodic memory - can be emulated to a nice degree using again nothing more than the above symbol-juggling mechanisms. If it looks like a duck, quacks like a duck, has the typical size and color of a duck, and is found near a pond in a park, a program may well deduce it is a duck even without really having 'seen' it, or having a 'mental picture' of a duck.
Let me reformulate in connection with some more famous AI philosophy stuffs. We can get far without grounding our symbols if you will. Or state it this way: they can be adequately 'grounded' just by having enough knowledge about them. A Chinese room book containing not just a huge lookup table but a set of rules to find the answer, is a thinking machine, etc... I am doing my homework as I'm going along, though there always seems to be more and more to learn. Part of the fun of this journey!
Obviously I am personally just hitting the very first baby steps of testing the above statement. But at least I am giving a shot at falsifying my belief, hooray for (mad) science! But, ahem. I disgress.
The real ultimate goal (and the reason I started this project) is seeing whether Yoko can be funny (and not by rehashing the author's wit), i.e. can we program some mechanisms/rules about how to use her knowledge for humor, and have reasonably funny jokes/quips come out - more on that in the language section.
Yoko is messy
Should you manage to read through all these 'about' pages, one thought may come to mind: Yoko is messy (or 'complex' if you want to be nice about it).
This puts Yoko in strong and obvious contrast with bots centering around a custom 'AI language', of which the most sofisticated and prominent publically available examples are probably AIML (by far the best known one) lead by Dr. Richard Wallace, ChatScript lead by Bruce Wilcox, and RiveScript lead by Noah Petherbridge. These are very powerful languages, that go far beyond simple 'pattern matching', and they represent the current state of the art judging by how well bots made with them tend to perform on the Loebner prize. (all three of these languages are also actively supported by the author and community at the chatbots.org forums)
Yoko, by contrast, uses PHP, which is orders of magnitude more powerful, expressive and general-purpose than any 'custom AI language', but comes with the heavy caveat that - as of yet - there is no such thing as a 'Yoko manual'. To 'get' the mechanisms behind the program on a more detailed level than what is described on these pages, one would need to know PHP and MySQL, and then read the source code.
Similar considerations surround the data being juggled around. The knowledge database (more on Yoko's knowledge) consists not of one nice 'hypergraph' or 'semantic net', but instead of more than a dozen different tables by now (list tables). Those tables tend to contain lots of rows. When starting from zero knowledge, the phrase 'my cat died today' does about 12 different INSERTs accross different 'knowledge' tables.
Language parsing and language generating are handled with an awkward 'template' language files and 'language lists' and tons of regexes sprinkled throughout the parsing. Lots of PHP handles the 'understanding'. Between input and output there are tons of regex searches, awkward explicit exceptions (asking about a 'name' is treated as a special case of a question about an instance's possession relation for example, as 'name' is a fundamental property stored with each instance)... Building Yoko it has become painfully obvious that a lot more complex language parsing will need to be added, and that adding stronger coupling between language and knowledge will probably be unavoidable. So much for 'modularity'. I've also found myself googling fun things to plug in exceptions to my crude grammar rules. ('names ending with an -s', to prevent users named James to be seen as a collection of class 'jame' etc...)
Reasoning is messy, being done in PHP, with separate routines for all kinds of different types of questions and statements, discarding punctuation and 'qualifier words' for questions and statements, but not so for sentiments (or ':)' would not be understood), something that seems math-y sends Yoko off on a math-solving tangent (no pun intended) etc... And I don't even want to try counting the 'foreach' loops between input and output.
... But that's ok.
Yoko is messy because language is messy. Language is messy because the world it describes is messy. The world is messy because we humans are amazingly complex beings, with brains that perceive, order and reason about that world in a rich myriad of different and adaptive ways. So naturally, code and data to capture all that will be large (but non-repetitive!) and filled with quirks, even when it only tries to achieve a very, very basic 'intelligence' like a 5-year old has. So be it. The fun is in the creating, improving, learning on how we think and how the 'real' AI people have thought about things, and, well, there's no deadline.
Cynically, maybe the biggest cause of messiness may be the fact that she is built by me, going about it in a bit of a 'storm in the room and shoot in all directions' fashion. Non-messiness (embodied in modularity, non-DRY...) of the code is a continuous priority though, so at least that shouldn't be a big cause of messiness. There Code built by one person having all of its different components in his head tends to run less risk of redundancy and non-optimal structuring than code that is a collaborative effort, too. So there's that.
What Yoko is not
The above means that Yoko is not very 'self-learning'. The grammar, the way knowledge about the world is represented, and the direct 'first try this than this than that' kinda reasoning in the conversation, are all separate bits and directly hard-coded by me, without any advanced statistics/clustering/neural nets/classification algoritms behind it. Only the data governing Yoko is dynamic and based on her input/output, really. And again, it is the contents of that data that is dynamic, its structure is rather rigid.
This is fine by me, and very much on purpose, because I want to keep
- understanding language,
- storing/retrieving/categorizing knowledge,
- reasoning (including emotions, humor, relating concepts to earlier ones...) and finally
- carrying a natural-feeling conversation
This also means that each of these aspects will be pretty damn basic compared to what's 'out there'. That's fine by me - and I'm secretly dreaming that because of Yoko's modularity, in some '2.0' version I will be able to leverage existing open-source components to boost each of these. (connecting a proper grammar parser, importing existing free ontologies, having Yoko learn about 'events' from real news sources, using a faster storage engine, yes why not use AIML to get more 'category templates' etc...)
Most current chatbots seem to lump most or all of the above together in one big 'AI scripting language' (often AIML), or by working purely 'learning' using statistical algorithms on big sets of text/conversation data (like JabberWacky) but I am having fun keeping them separated, and reflecting on how things work for each of these aspects.
This means the data about the world is in a MySQL database (with the data model coded by me), the grammar is defined in my 'Natural Language Understanding' parser (defined in .json files using a simple template language - probably the component most similar to AIML - and making a 'decision' on what to say to keep the conversation going. The kind of bots that followed this approach seemed to have stopped being built beyond the 60ies (like STUDENT and SHRDLU), but after that the world lost interest. Shame, because we have faster databases and higher-level languages now (though arguably LISP is pretty damn high-level), and can build chat interfaces that people can chat to online, etc.
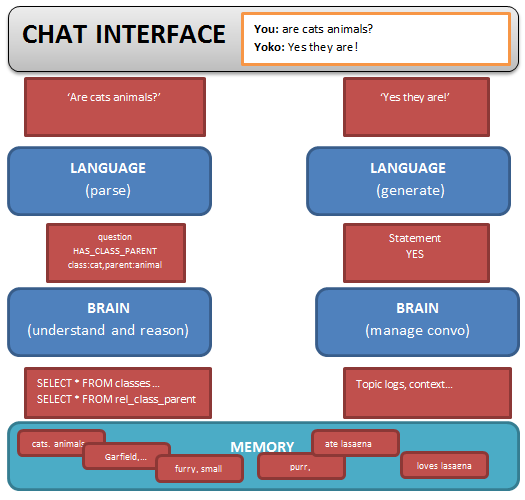
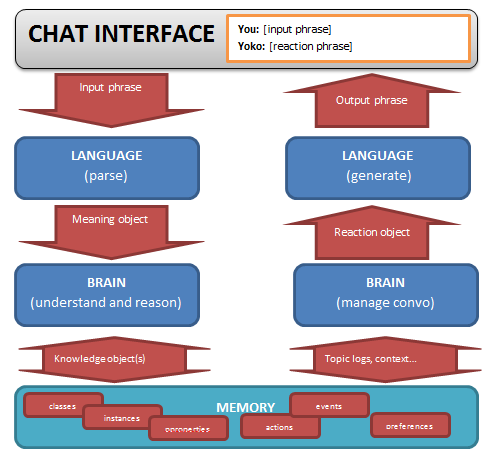
From input to output: code modules and data
Hooray for charts!
SPECIFIC EXAMPLE: